This post belongs to the Headless CMS fun with Phoenix LiveView and Airtable series.
- Introduction.
- The project set up and implementing the repository pattern.
- Content rendering using Phoenix LiveView.
- Adding a cache to the repository and broadcasting changes to the views..
In the previous part, we talked about Phoenix LiveView and implemented all the necessary views and templates to render all the content on our website. Each live view requests its contents to Airtable on its mount function, assigning them in its state. At first, it sounds like a proper implementation, similar to what we would have done using Ecto and a database to store the contents. However, the current solution has three main issues:
- Using HTTP to request content against an external service adds an overhead to the initial page load, slowing down page loads.
- If, for whatever reason, the external service is down, we won’t be able to display any content to our visitors.
- Last but not least, Airtable is limited to 5 requests per second per base. If we exceed this rate, it will return a 429 status code, and we’ll need to wait 30 seconds before a new request succeeds.
So, how can we solve these issues? The solution we are going to implement consists of adding an in-memory cache to the repository, which stores both the contents and the articles, and synchronizes every second with Airtable. This way, we remove the additional overhead, render content even if Airtable happens to be down, and we control the number of requests per second done in a single place. Let’s do this!
The repository cache
Erlang/OTP/Elixir comes with a robust in-memory term storage, called ETS, out of the box. It can store large amounts of data offering constant time data access. ETS organizes data as a set of dynamic tables, consisting of tuples, containing a key and the stored term. Tables are created by a process that is its owner and deleted when this process dies. In Elixir, ETS tables are often managed using a GenServer process, and in our particular case, we need two different tables, ergo two different cache processes, one to store PhoenixCms.Content terms and the other to store PhoenixCms.Article. Knowing this, let’s implement the generic GenServer cache definition:
# lib/phoenix_cms/repo/cache.ex
defmodule PhoenixCms.Repo.Cache do
use GenServer
@callback table_name :: atom
@callback start_link(keyword) :: GenServer.on_start()
@impl GenServer
def init(name) do
name
|> table_for()
|> :ets.new([:ordered_set, :protected, :named_table])
{:ok, %{name: name}}
end
defp table_for(name), do: apply(name, :table_name, [])
end
This module defines the behavior that any cache process must fulfill, which is initially a table_name/0 function, which returns the ETS table name for that cache and a start_link/1 function, which defines how the cache process starts. The module also defines the generic logic of a cache process, like the init/1 function, which using name with the private table_for/1 function, gets the table name, depending on the current cache module, and creates the ETS table using the following parameters:
-
name, an atom representing the table’s name, in our case:articlesor:contents. -
:ordered_set, which specifies the type of the table, in our case, an ordered set that contains a value per unique key. -
:protected, which sets the access control, in our case read is available for all processes, but write operations are permitted only from the owner process, avoiding race conditions. -
:named_table, makes the table accessible by name instead of the by its PID.
Finally, it sets the initial process state to a map containing the cache module name, which we’ll use later on. Now let’s define the specific cache modules:
# lib/phoenix_cms/article/cache.ex
defmodule PhoenixCms.Article.Cache do
alias PhoenixCms.Repo.Cache
@behaviour Cache
def child_spec(opts) do
%{
id: __MODULE__,
start: {__MODULE__, :start_link, [opts]},
type: :worker,
restart: :permanent,
shutdown: 500
}
end
@impl Cache
def table_name, do: :articles
@impl Cache
def start_link(_args) do
GenServer.start_link(Cache, __MODULE__, name: __MODULE__)
end
end# lib/phoenix_cms/content/cache.ex
defmodule PhoenixCms.Content.Cache do
alias PhoenixCms.Repo.Cache
@behaviour Cache
def child_spec(opts) do
%{
id: __MODULE__,
start: {__MODULE__, :start_link, [opts]},
type: :worker,
restart: :permanent,
shutdown: 500
}
end
@impl Cache
def table_name, do: :contents
@impl Cache
def start_link(_args) do
GenServer.start_link(Cache, __MODULE__, name: __MODULE__)
end
end
Both modules fulfill the PhoenixCms.Repo.Cache behavior by implementing the table_name/0 function, which returns the corresponding table name, and start_link/1, starts a new PhoenixCms.Repo.Cache GenServer, and uses their module name to set the initial state and name the process. To start both cache processes when the application starts, let’s add them to the main supervision tree:
# lib/phoenix_cms/application.ex
defmodule PhoenixCms.Application do
use Application
def start(_type, _args) do
children = [
# ...
# Start cache processes
PhoenixCms.Article.Cache,
PhoenixCms.Content.Cache,
# ...
]
opts = [strategy: :one_for_one, name: PhoenixCms.Supervisor]
Supervisor.start_link(children, opts)
end
# ...
endTo check that everything works fine, let’s start IEX and get the cache processes info:
➜ iex -S mix
Erlang/OTP 23 [erts-11.0.2] [source] [64-bit] [smp:8:8] [ds:8:8:10] [async-threads:1]
Interactive Elixir (1.10.4) - press Ctrl+C to exit (type h() ENTER for help)
iex(1)> PhoenixCms.Article.Cache |> GenServer.whereis() |> Process.info()
[
registered_name: PhoenixCms.Article.Cache,
current_function: {:gen_server, :loop, 7},
initial_call: {:proc_lib, :init_p, 5},
status: :waiting,
message_queue_len: 0,
links: [#PID<0.318.0>],
dictionary: [
"$initial_call": {PhoenixCms.Repo.Cache, :init, 1},
"$ancestors": [PhoenixCms.Supervisor, #PID<0.317.0>]
],
trap_exit: false,
error_handler: :error_handler,
priority: :normal,
group_leader: #PID<0.316.0>,
total_heap_size: 233,
heap_size: 233,
stack_size: 12,
reductions: 44,
garbage_collection: [
max_heap_size: %{error_logger: true, kill: true, size: 0},
min_bin_vheap_size: 46422,
min_heap_size: 233,
fullsweep_after: 65535,
minor_gcs: 0
],
suspending: []
]
iex(2)> PhoenixCms.Content.Cache |> GenServer.whereis() |> Process.info()
[
registered_name: PhoenixCms.Content.Cache,
current_function: {:gen_server, :loop, 7},
initial_call: {:proc_lib, :init_p, 5},
status: :waiting,
message_queue_len: 0,
links: [#PID<0.318.0>],
dictionary: [
"$initial_call": {PhoenixCms.Repo.Cache, :init, 1},
"$ancestors": [PhoenixCms.Supervisor, #PID<0.317.0>]
],
trap_exit: false,
error_handler: :error_handler,
priority: :normal,
group_leader: #PID<0.316.0>,
total_heap_size: 233,
heap_size: 233,
stack_size: 12,
reductions: 44,
garbage_collection: [
max_heap_size: %{error_logger: true, kill: true, size: 0},
min_bin_vheap_size: 46422,
min_heap_size: 233,
fullsweep_after: 65535,
minor_gcs: 0
],
suspending: []
]
Since the processes are up, both ETS tables must have been created as well, let’s confirm it:
iex(3)> :ets.info(:articles)
[
id: #Reference<0.2785746427.4276748289.246266>,
decentralized_counters: false,
read_concurrency: false,
write_concurrency: false,
compressed: false,
memory: 145,
owner: #PID<0.326.0>,
heir: :none,
name: :articles,
size: 0,
node: :nonode@nohost,
named_table: true,
type: :ordered_set,
keypos: 1,
protection: :protected
]
iex(4)> :ets.info(:contents)
[
id: #Reference<0.2785746427.4276748289.246267>,
decentralized_counters: false,
read_concurrency: false,
write_concurrency: false,
compressed: false,
memory: 145,
owner: #PID<0.327.0>,
heir: :none,
name: :contents,
size: 0,
node: :nonode@nohost,
named_table: true,
type: :ordered_set,
keypos: 1,
protection: :protected
]
iex(5)>There we go! And if we check both cache processes PIDs, they should match their corresponding table owner’s PID:
iex(5)> GenServer.whereis(PhoenixCms.Article.Cache)
#PID<0.326.0>
iex(6)> GenServer.whereis(PhoenixCms.Content.Cache)
#PID<0.327.0>
iex(7)>Let’s add some helper functions to the cache module to get and set data from the corresponding ETS table:
# lib/phoenix_cms/repo/cache.ex
defmodule PhoenixCms.Repo.Cache do
# ...
def all(cache) do
cache
|> table_for()
|> :ets.tab2list()
|> case do
values when values != [] ->
{:ok, Enum.map(values, &elem(&1, 1))}
_ ->
{:error, :not_found}
end
end
def get(cache, key) do
cache
|> table_for()
|> :ets.lookup(key)
|> case do
[{^key, value} | _] ->
{:ok, value}
_ ->
{:error, :not_found}
end
end
def set_all(cache, items), do: GenServer.cast(cache, {:set_all, items})
def set(cache, id, item), do: GenServer.cast(cache, {:set, id, item})
# ...
@impl GenServer
def handle_cast({:set_all, items}, %{name: name} = state)
when is_list(items) do
Enum.each(items, &:ets.insert(table_for(name), {&1.id, &1}))
{:noreply, state}
end
def handle_cast({:set, id, item}, %{name: name} = state) do
name
|> table_for()
|> :ets.insert({id, item})
{:noreply, state}
end
endLet’s take a closer look at them:
-
all/1takes the cache module, which uses to get the table name and calls:ets.tab2list/1, which returns all the entry tuples of a given table, which maps to a list of values, or an{:error, :not_found}if empty. -
get/2receives the cache module and a key, and does the same asall/1. -
set_all/2andset/3are different tho. Since we configured the table as protected, we can only insert data from the process which created the table. Therefore, it sends the corresponding messages to the processes usingGensServer.cast/2. It implements both message callback functions, which insert all of the given entries or a given entry by its ID correspondently.
Let’s refactor the repository module to include the cache in its logic, and avoid unnecessary HTTP requests when the data already exists in the cache:
# lib/phoenix_cms/repo.ex
defmodule PhoenixCms.Repo do
alias PhoenixCms.{Article, Content}
# ...
def articles(skip_cache \\ false)
def articles(false), do: all(Article)
def articles(true), do: @adapter.all(Article)
def contents(skip_cache \\ false)
def contents(false), do: all(Content)
def contents(true), do: @adapter.all(Content)
def get_article(id), do: get(Article, id)
defp all(entity) do
with cache <- cache_for(entity),
{:error, :not_found} <- Cache.all(cache),
{:ok, items} <- @adapter.all(entity) do
Cache.set_all(cache, items)
{:ok, items}
end
end
defp get(entity, id) do
with cache <- cache_for(entity),
{:error, :not_found} <- Cache.get(cache, id),
{:ok, item} <- @adapter.get(entity, id) do
Cache.set(cache, id, item)
{:ok, item}
end
end
defp cache_for(Article), do: PhoenixCms.Article.Cache
defp cache_for(Content), do: PhoenixCms.Content.Cache
end
We are adding a new skip_cache parameter that when is false, instead of directly calling the adapter in the public functions, now it checks if the requested items exist in the cache, calling the adapter if not and populating them. Hence, the next request has the data already cached. When it is true, it uses the adapter directly, skipping the cache, and we’ll use this variation in a minute. Let’s navigate through the application checking out the logs:
>>>>>>> Homepage first visit
[info] GET /
[info] GET https://api.airtable.com/v0/appXTw8FgG3h55fk6/contents -> 200 (663.964 ms)
[info] Sent 200 in 834ms
>>>>>>> Blog page first visit
[info] GET /blog
[info] Sent 200 in 400µs
[info] GET https://api.airtable.com/v0/appXTw8FgG3h55fk6/articles -> 200 (225.874 ms)
>>>>>>> Blog detail first visit
[info] GET /blog/rec1osLptzsXfWg5g/lorem-ipsum
[info] Sent 200 in 422µs
>>>>>>> Homepage second visit
[info] GET /
[info] Sent 200 in 456µs
>>>>>>> Blog page second visit
[info] GET /blog
[info] Sent 200 in 531µsThe first time we visit the home and blog pages, it performs the corresponding HTTP requests against Airtable. However, when visiting an article page, since the article has already been cached from the previous request, it does not need to request it. The same happens when we visit both the home and blog pages a second time.
Synchronizing the caches
Although the current cache implementation covers the issues that we have using the HTTP client directly, we now face a new problem. If we update any data stored in Airtable, the changes will not be reflected in our application, as the cache is already populated. Currently, Airtable does not have any mechanism to report data changes, such as webhooks. Nevertheless, we can achieve this using services like Zapier, but it only works for new rows or row deletions, not for updates, which is not suitable for our needs. Therefore, let’s build or own cache synchronization solution, which is very easy, thanks to Elixir.
The main idea is to have two new processes, one for each cache, that periodically make requests against Airtable, updating their corresponding cache if there are new changes. Let’s define the new module:
# lib/phoenix_cms/repo/cache/synchronizer.ex
defmodule PhoenixCms.Repo.Cache.Synchronizer do
alias PhoenixCms.Repo.Cache
use GenServer
@refresh_time :timer.seconds(1)
def start_link(opts) do
GenServer.start_link(__MODULE__, opts)
end
@impl GenServer
def init(opts) do
cache = Keyword.fetch!(opts, :cache)
send(self(), :sync)
{:ok, cache}
end
@impl GenServer
def handle_info(:sync, cache) do
with {:ok, items} <- apply(cache, :fetch_fn, []).() do
Cache.set_all(cache, items)
end
schedule(cache)
{:noreply, cache}
end
defp schedule(cache) do
Process.send_after(self(), :sync, @refresh_time)
end
end
One more time, we are using GenServer for the new process. Itsinit/1 function takes the mandatory cache key from the options, which can contain either PhoenixCms.Article.Cache or PhoenixCms.Content.Cache, and sets it as the initial state of the process. It also sends itself a :sync message, which handles in the handle_info(:sync, cache) callback, applying the :fetch_fn function to the cache module, and setting the items in the cache if the request succeeds. Finally, it calls the schedule/1 private function, which sends the :sync message again after one second. So, we now have a process that requests the corresponding data to Airbrake every second, updating the corresponding cache table. Now we need to start these processes, so let’s refactor the cache module:
# lib/phoenix_cms/repo/cache.ex
defmodule PhoenixCms.Repo.Cache do
use GenServer
alias __MODULE__.Synchronizer
@callback fetch_fn :: fun
# ...
@impl GenServer
def init(name) do
Process.flag(:trap_exit, true)
name
|> table_for()
|> :ets.new([:ordered_set, :protected, :named_table])
{:ok, pid} = Synchronizer.start_link(cache: name)
ref = Process.monitor(pid)
{:ok, %{name: name, synchronizer_ref: ref}}
end
# ...
@impl GenServer
def handle_info(
{:DOWN, ref, :process, _object, _reason},
%{synchronizer_ref: ref, name: name} = state
) do
{:ok, pid} = Synchronizer.start_link(cache: name)
ref = Process.monitor(pid)
{:noreply, %{state | synchronizer_ref: ref}}
end
def handle_info({:EXIT, _, _}, state) do
{:noreply, state}
end
# ...
endOnce the cache process initializes, it creates the corresponding ETS table as it was doing before and starts its synchronizer process. Since the synchronizer process links to the cache process, it does the following:
-
First of all, it traps exits, so if the synchronizer dies, it does not kill the cache process, implementing
handle_info({:EXIT, _, _}, state). -
Secondly, it monitors the synchronizer process, storing the monitor ref in its state, so in case the synchronizer process dies, it spawns a new one in
handle_info( {:DOWN, ref, :process, _, _}, %{synchronizer_ref: ref), so that the cache keeps up to date with its source of truth, which is Airtable.
Finally, we need to implement the fetch_fn/0 function in the cache modules:
# lib/phoenix_cms/article/cache.ex
defmodule PhoenixCms.Article.Cache do
alias PhoenixCms.{Repo, Repo.Cache}
@behaviour Cache
# ...
@impl Cache
def fetch_fn, do: fn -> Repo.articles(true) end
end# lib/phoenix_cms/content/cache.ex
defmodule PhoenixCms.Content.Cache do
alias PhoenixCms.{Repo, Repo.Cache}
@behaviour Cache
# ...
@impl Cache
def fetch_fn, do: fn -> Repo.contents(true) end
end
Each function calls the corresponding repository, passing true as the skip_cache parameter so that it always checks against Airtable. Let’s go back to IEX and start :observer to check the application tree:
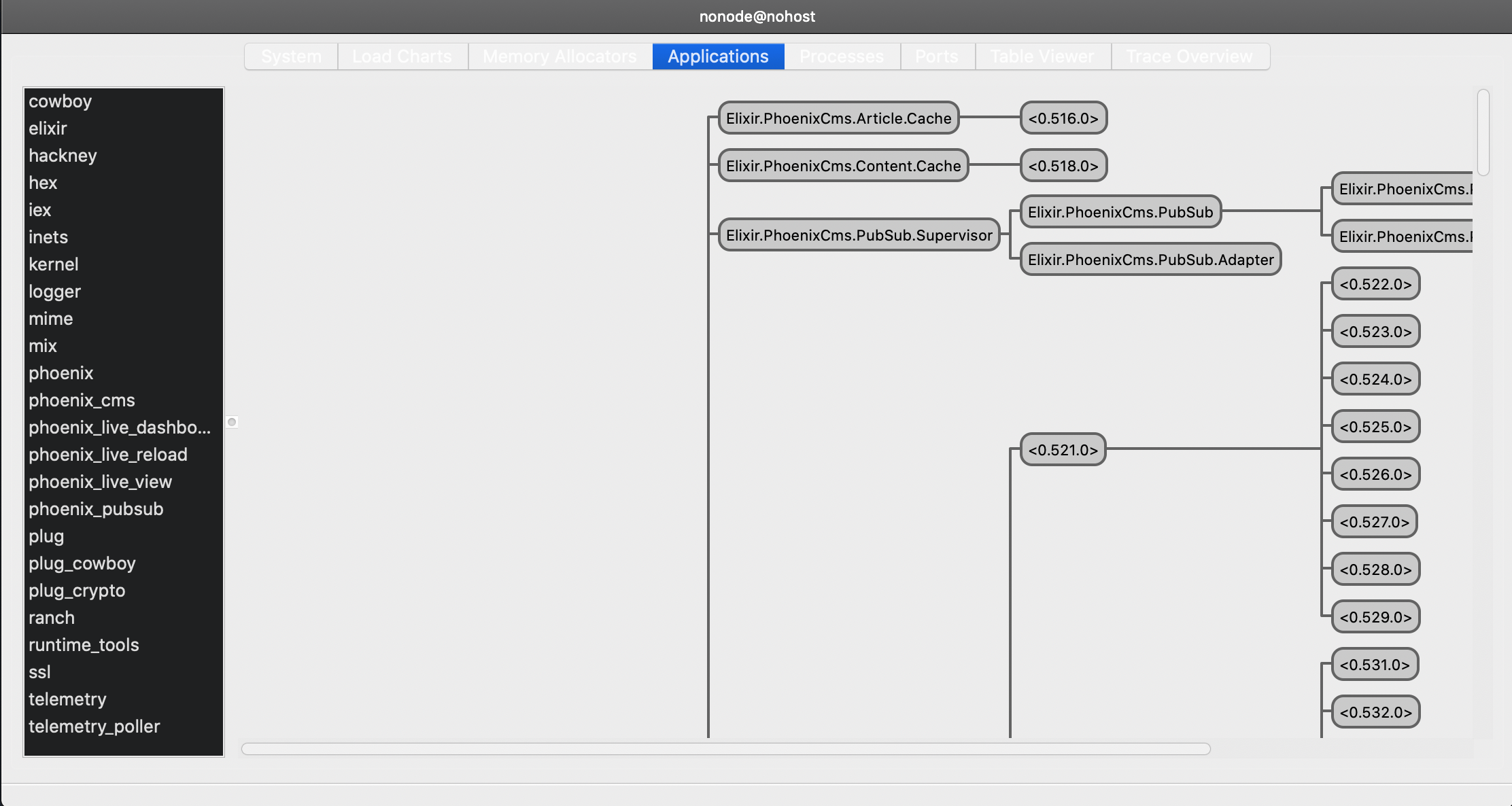
We can see both the PhoenixCms.Article.Cache and PhoenixCms.Content.Cache processes, each of them linked to their PhoenixCms.Repo.Cache.Synchronizer process. And if we check the logs, we can see the following:
iex(3)> [info] GET https://api.airtable.com/v0/appXTw8FgG3h55fk6/articles -> 200 (126.214 ms)
[info] GET https://api.airtable.com/v0/appXTw8FgG3h55fk6/contents -> 200 (121.886 ms)
[info] GET https://api.airtable.com/v0/appXTw8FgG3h55fk6/articles -> 200 (123.290 ms)
[info] GET https://api.airtable.com/v0/appXTw8FgG3h55fk6/contents -> 200 (125.372 ms)
[info] GET https://api.airtable.com/v0/appXTw8FgG3h55fk6/articles -> 200 (140.528 ms)
[info] GET https://api.airtable.com/v0/appXTw8FgG3h55fk6/contents -> 200 (116.197 ms)
[info] GET https://api.airtable.com/v0/appXTw8FgG3h55fk6/articles -> 200 (123.440 ms)
[info] GET https://api.airtable.com/v0/appXTw8FgG3h55fk6/contents -> 200 (121.408 ms)
[info] GET https://api.airtable.com/v0/appXTw8FgG3h55fk6/articles -> 200 (121.811 ms)
[info] GET https://api.airtable.com/v0/appXTw8FgG3h55fk6/contents -> 200 (118.887 ms)
[info] GET https://api.airtable.com/v0/appXTw8FgG3h55fk6/articles -> 200 (437.112 ms)If we now change anything in Airtable, and we refresh the browser tab with our application, it should render the modifications correctly.
Real-time UI updates
We currently have everything working as planned. All the content is stored in an external service, and we get the content using an HTTP client pointing to its API. We also have a cache mechanism that auto-updates the stored data, and which prevents the repository from making additional HTTP requests. Finally, we display all the content using Phoenix LiveView, which lets us render updates in the UI in real-time. But, wait a sec! With our current implementation, that we have to refresh the browser manually to display content updates, we could have used regular Phoenix views. So what’s the point of using LiveView anyways? The point is that we can broadcast changes to live views, which will render them to the visitor without having to refresh the browser whatsoever.
To broadcast changes to the view, we are going to be using Phoenix.PubSub, which comes by default with Phoenix. Let’s do some refactoring to the cache module:
# lib/phoenix_cms/repo/cache.ex
defmodule PhoenixCms.Repo.Cache do
use GenServer
alias __MODULE__.Synchronizer
# ...
@callback topic :: String.t()
@secret "cache secret"
# ...
@impl GenServer
def init(name) do
# ...
{:ok, %{name: name, synchronizer_ref: ref, hash: ""}}
end
# ...
@impl GenServer
def handle_cast({:set_all, items}, %{name: name, hash: hash} = state)
when is_list(items) do
new_hash = generate_hash(items)
if hash != new_hash do
Enum.each(items, &:ets.insert(table_for(name), {&1.id, &1}))
PhoenixCmsWeb.Endpoint.broadcast(apply(name, :topic, []), "update", %{})
end
{:noreply, %{state | hash: new_hash}}
end
# ...
defp generate_hash(items) do
:sha256
|> :crypto.hmac(@secret, :erlang.term_to_binary(items))
|> Base.encode64()
end
end
First of all, we are defining a new callback function to the repository behavior, topic, which must return the topic in which we are going the broadcast the changes in the current cache. In the initial state, we are also adding a new hash empty string. While handling {:set_all, items} messages, we generate a new hash of with the items, and if the hash is different to the one stored in the state, it inserts all the items in the ETS table, like it previously did, and calls PhoenixCmsWeb.Endpoint.broadcast/3, using the :topic function from the cache module. Finally, it sets the new hash in its state. This way, we are reporting to any subscriber of topic that there are changes when the hashes are different. Moreover, it is also storing them and preventing unnecessary writes when there are no data differences.
Let’s implement the topic function in both cache modules:
# lib/phoenix_cms/article/cache.ex
defmodule PhoenixCms.Article.Cache do
alias PhoenixCms.{Repo, Repo.Cache}
@behaviour Cache
@topic "articles"
# ...
@impl Cache
def topic, do: @topic
end# lib/phoenix_cms/content/cache.ex
defmodule PhoenixCms.Content.Cache do
alias PhoenixCms.{Repo, Repo.Cache}
@behaviour Cache
@topic "contents"
# ...
@impl Cache
def topic, do: @topic
endThe last step is to subscribe to the corresponding topics in the live views:
# lib/phoenix_cms_web/live/page_live.ex
defmodule PhoenixCmsWeb.PageLive do
use PhoenixCmsWeb, :live_view
@topic "contents"
@impl true
def mount(_params, _session, socket) do
PhoenixCmsWeb.Endpoint.subscribe(@topic)
{:ok, assign_socket(socket)}
end
@impl true
def handle_info(%{event: "update"}, socket) do
{:noreply, assign_socket(socket)}
end
# ...
end
# lib/phoenix_cms_web/live/articles_live.ex
defmodule PhoenixCmsWeb.ArticlesLive do
use PhoenixCmsWeb, :live_view
alias PhoenixCmsWeb.LiveEncoder
@topic "articles"
@impl true
def mount(_params, _session, socket) do
PhoenixCmsWeb.Endpoint.subscribe(@topic)
{:ok, assign_socket(socket)}
end
@impl true
def handle_info(%{event: "update"}, socket) do
{:noreply, assign_socket(socket)}
end
# ...
end
# lib/phoenix_cms_web/live/show_article_live.ex
defmodule PhoenixCmsWeb.ShowArticleLive do
use PhoenixCmsWeb, :live_view
@topic "articles"
@impl true
def mount(%{"id" => id}, _session, socket) do
PhoenixCmsWeb.Endpoint.subscribe(@topic)
{:ok, assign_socket(socket, id)}
end
@impl true
def handle_info(%{event: "update"}, socket) do
id = socket.assigns.article.id
{:noreply, assign_socket(socket, id)}
end
# ...
end
In the mount/3 function, each view subscribes to the relevant topic. Once the view process adheres to the topic, it needs to handle incoming messages using handle_info/2, which reassigns the socket contents, triggering a new render in the visitor’s screen. Let’s jump back to the browser, change something in Airtable, and watch what happens in our application:
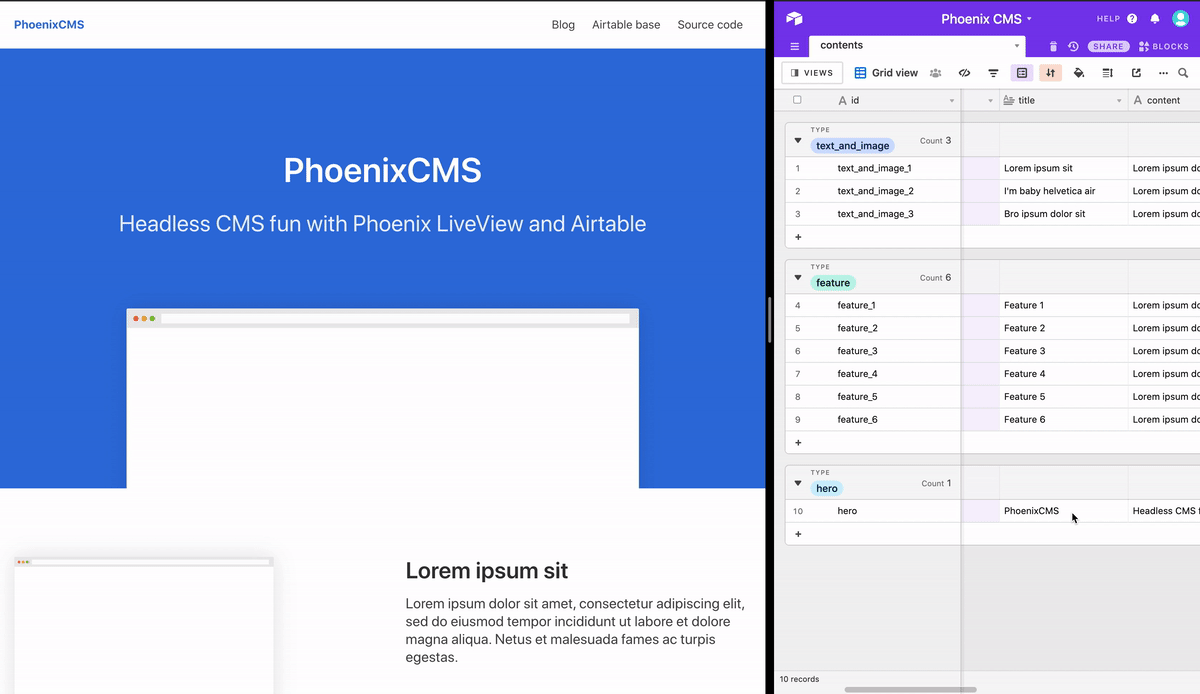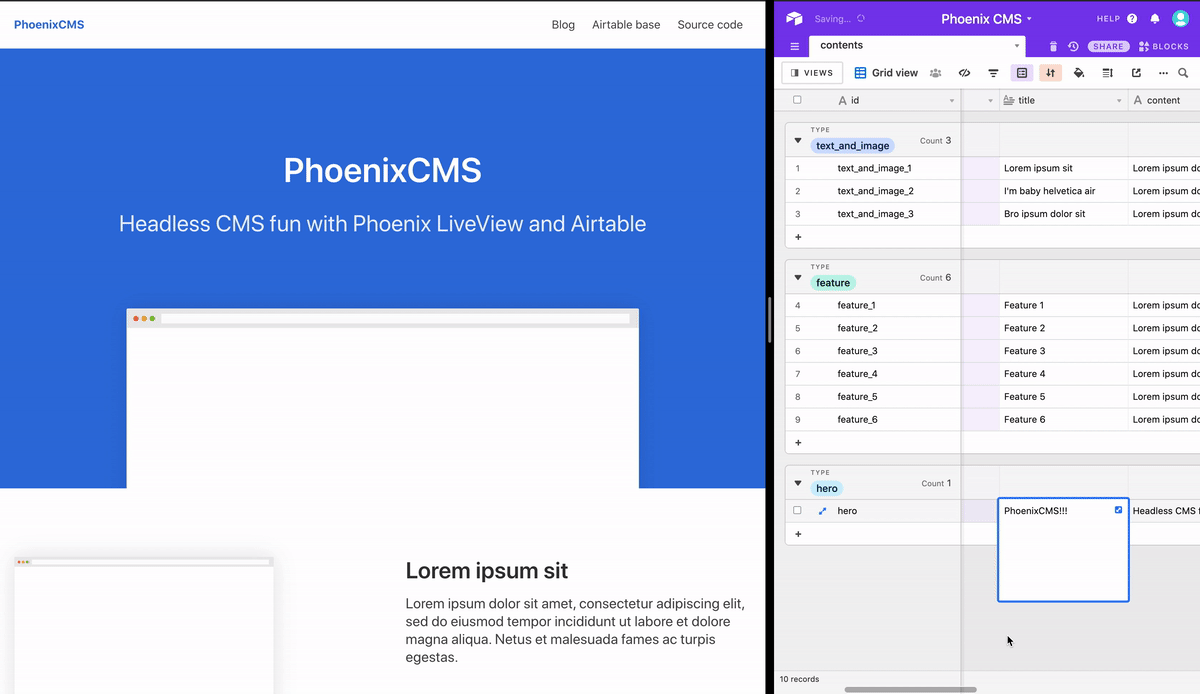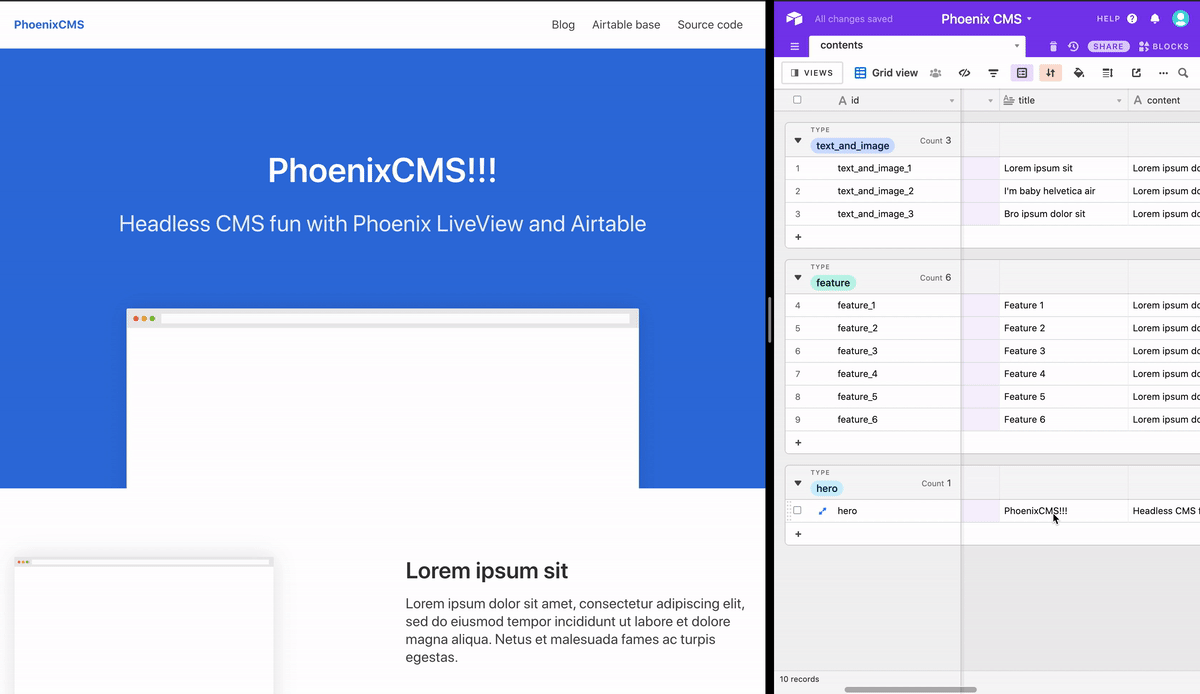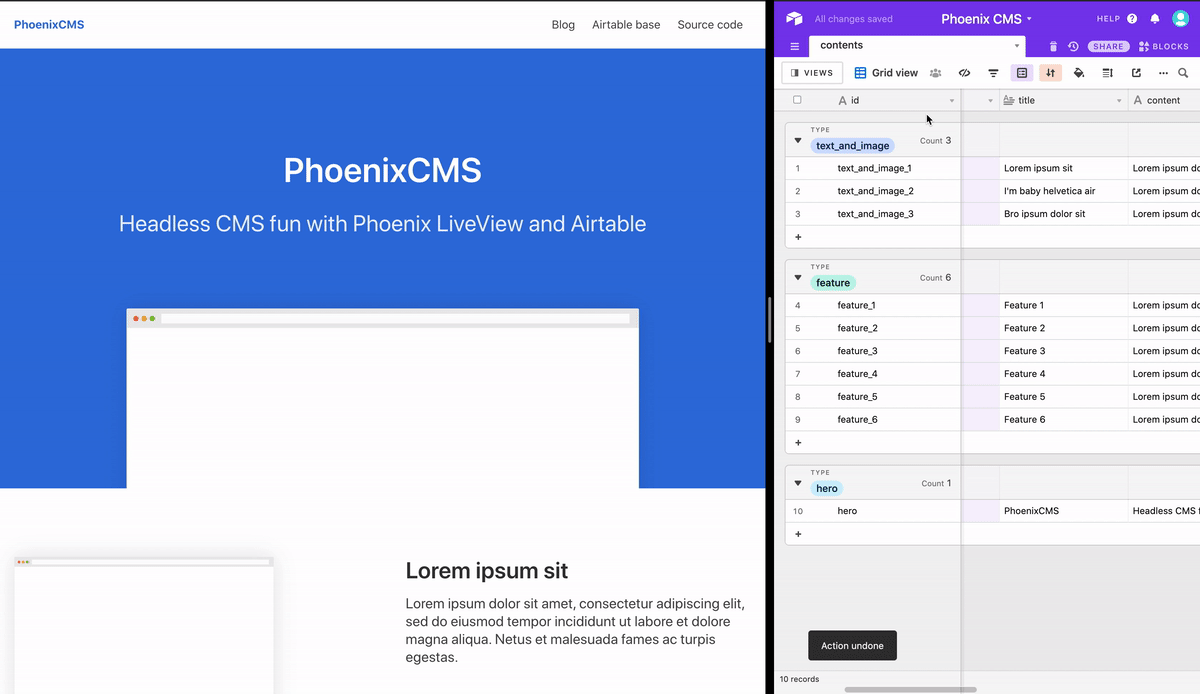
It works! We finally have finished our simple CMS using Phoenix and Airtable, yay! I hope you enjoyed this tutorial as much as I enjoyed writing it and implementing it. You can check the final result here, or have a look at the source code.
Happy coding!